什么是嵌入(Embedding)
嵌入,一般常用于搜索查询中寻找最相关的结果,通过将文本内容按照相似度分组,推荐类似的内容,查找差异最大的文本,分析文本之间的差异程度,并对文本进行标记等任务。 简单来说:OpenAI的文本嵌入可以度量两个文本字符串有多么相似。
使用场景
- NLP任务,比如情感分析、语义相似度、情绪分类
- 为机器学习的模型,比如关键词匹配、文档分类、话题建模,提供文本嵌入功能。
- 为文本生成语言无关的表示,开展跨语言的文本比较
- 为文本搜索引擎和自然语言理解系统提升精度
- 通过对比用户输入的文本和一大批文本字符串,创建个性化推荐
主要归纳为: - 搜索:根据和查询语句的相关性对结果排序
- 聚类:将文本根据其相似度进行分组
- 推荐:推荐和文本相关的东西
- 异常检测:识别相关性不大的异常点
- 多样性测量:分析相似度分布
- 分类:根据既定的标签对文本进行分类 具体原理不做赘述,可以查阅相关档: 一文读懂Embedding的概念,以及它和深度学习的关系
OpenAi中使用Embedding
OpenAI官网文档
Embeddings - OpenAI API 目前推荐使用:text-embedding-ada-002
python中调用文本嵌入
- 我们简单嵌入一句
response = openai.Embedding.create(
model="text-embedding-ada-002",
input="I am a programmer",
)
print(response)
- 注意:每一条输入都不应该超过8192个token的长度
- 输出结果如下:
{
"data": [
{
"embedding": [
-0.0169205479323864,
-0.019740639254450798,
-0.011300412937998772,
-0.016452759504318237,
[..]
0.003966170828789473,
-0.011714739724993706
],
"index": 0,
"object": "embedding"
}],
"model": "text-embedding-ada-002-v2",
"object": "list",
"usage": {
"prompt_tokens": 4,
"total_tokens": 4
}
}
也可以通过print(response["embedding"])直接访问嵌入结果,程序会输出诸如0.013211660087108612的浮点数。
嵌入方法是对输入文本的一种高维表示,可以捕获其含义。它有时候也指代向量表示,或者一个嵌入向量。
调用OpenAi计算向量相似度(余弦相似度)
- 这里也不做赘述具体计算逻辑,具体逻辑看文档:
Python实现
from openai.embeddings_utils import cosine_similarity
cosine_similarity(向量值1, 向量值2)
ChatGPT调用
- 相关文档:
- 这里用gpt-3.5-turbo为例,一个简单的调用如下:
- url:
https://api.openai.com/v1/chat/completions - Headers:
- Authorization:Bearer api-key
- Body
{ "model": "gpt-3.5-turbo", "messages": [{"role": "user", "content": "消息"}] }
- url:
Embedding和ChatGPT进行整合,实现知识库索引
这里借助gpt_index的逻辑图:
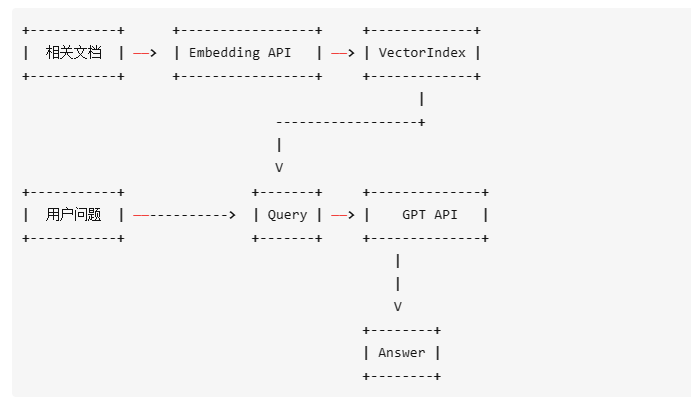 如果用户想要构建自己的知识库,知识库一旦变大,很明显会出现Token消耗的问题。如何缓解Token和定制Token消耗,我们需要借助
如果用户想要构建自己的知识库,知识库一旦变大,很明显会出现Token消耗的问题。如何缓解Token和定制Token消耗,我们需要借助Word embedding这个机制。
利用Python实现Demo
安装相关库
pip install datalib matplotlib plotly scipy scikit-learn
初始化和导入相关包
import numpy as np
import openai
import pandas as pd
from openai.embeddings_utils import get_embedding # 获取对应向量
from openai.embeddings_utils import cosine_similarity # 计算相似度
openai.api_key = "sk-xxxxx"
openai.proxy = "http://127.0.0.1:7890" # 配置代理
目录结构如下
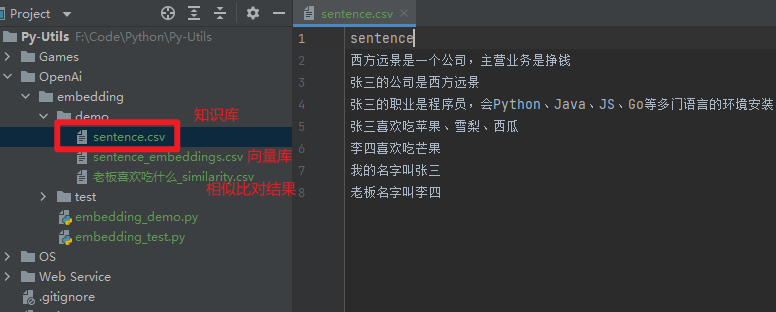
- demo/sentence.csv:简单知识库
sentence
西方远景是一个公司,主营业务是挣钱
张三的公司是西方远景
张三的职业是程序员,会Python、Java、JS、Go等多门语言的环境安装
张三喜欢吃苹果、雪梨、西瓜
李四喜欢吃芒果
我的名字叫张三
老板名字叫李四
- sentence_embeddings.csv:用来存储每个句子的向量值
- xxxx_similarity.csv:某个语句对应知识库的词向量相似度
计算知识库里面的向量值:
def compute_vector():
"""
将sentence.csv里面所有句子转换为向量值
:rtype: object
"""
df = pd.read_csv('demo/sentence.csv')
df['embedding'] = df['sentence'].apply(lambda x: get_embedding(x, engine='text-embedding-ada-002'))
df.to_csv('demo/sentence_embeddings.csv')
获取用户输入的语句,计算向量。比对余弦相似度
- 将df中的向量数组转换为numpy数组:numpy的数组广泛应用于数值计算中。普通的数组对这类计算毫无帮助。此外,numpy数组的内存开销更少,速度更快。这是因为numpy数组是同构的数据类型集合,保存在连续的内存空间中,而普通的Python列表不是的
def search_vector():
"""
根据用户输入读取向量值,使用cosine_similarity可以计算两个嵌入之间的余弦相似度
:rtype: object
"""
df = pd.read_csv('demo/sentence_embeddings.csv')
df['embedding'] = df['embedding'].apply(eval).apply(np.array) # 转换成numpy数组
user_search = input('输入检索语句: ')
user_search_embedding = get_embedding(user_search, engine='text-embedding-ada-002')
df['similarity'] = df['embedding'].apply(lambda x: cosine_similarity(x, user_search_embedding)) # 计算所有嵌入之间的余弦相似度
df.to_csv('demo/'+user_search+'_similarity.csv') # 保存相似度数据
获取相似结果
similarity值越高表示句子的关联性越大
这里我们用:老板喜欢吃什么做为问句进行相似度比较

将相似结果构建成上下文,加上问句提交给ChatGPT
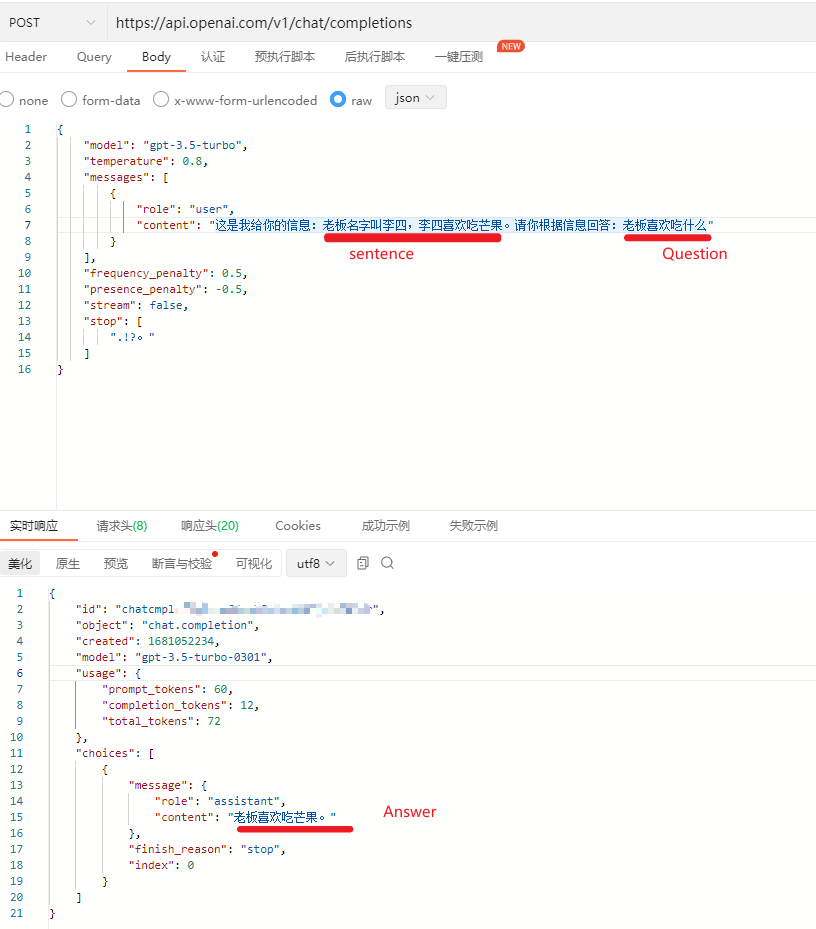
这里用简单的api来举例:
这里我们将检索匹配到的词向量相似度前2的语句提交给了GPT作为上下文。模板为:
这是我给你的信息:sentence。请你根据信息回答:Question
总结
- 上述DEMO只是一个简单的示例,实际的场景可能更为复杂。例如涉及到的文本内容过大的时候,可能需要对embedding进行多次的拆分…
- 另外后续可以尝试使用gpt_index,也是基于openai的text-embedding-ada-002模型来做嵌入。
...